第十四章 云原生架构设计理论与实践 数据处理服务的核心构建与演进
在当今数据驱动的时代,数据处理已成为企业数字化转型的核心引擎。云原生架构以其弹性、可扩展性和敏捷性,为数据处理服务的设计与实践提供了全新的范式。本章将深入探讨云原生架构下数据处理服务的设计原则、关键技术组件及其实践路径。
一、云原生数据处理服务的设计原则
云原生数据处理服务的设计遵循一系列核心原则,确保其在动态、分布式的云环境中高效运行:
- 弹性与可扩展性:服务应能根据数据负载自动伸缩,利用容器化技术(如Docker)和编排系统(如Kubernetes)实现资源的动态分配,避免性能瓶颈与资源浪费。
- 松耦合与微服务化:将复杂的数据处理流程拆分为独立的微服务,每个服务专注于单一功能(如数据摄取、清洗、分析或存储),通过API进行通信,提升系统的可维护性与部署灵活性。
- 事件驱动与流式处理:采用事件驱动架构(EDA)和流处理框架(如Apache Kafka、Flink),支持实时或近实时的数据处理,满足对低延迟洞察的迫切需求。
- 可观测性与韧性:集成日志记录、指标监控和分布式追踪(如Prometheus、Jaeger),实现服务运行状态的透明可视;通过重试、熔断和降级等模式增强系统容错能力。
- 声明式配置与自动化:使用基础设施即代码(IaC)工具(如Terraform)和声明式配置管理,确保数据处理管道的可重复部署与一致性,减少人工干预。
二、关键技术组件与架构模式
一个典型的云原生数据处理服务栈通常包含以下层次与组件:
- 数据摄取层:负责从多样化源(数据库、IoT设备、日志文件等)收集数据,常借助Change Data Capture(CDC)工具或消息队列实现高效、低侵入的数据同步。
- 处理与计算层:这是核心层,可进一步划分为批处理(使用Spark、AWS Glue等)和流处理(使用Kafka Streams、Google Dataflow等)。无服务器计算(如AWS Lambda)也日益流行,用于事件触发的轻量级处理任务。
- 存储层:采用多模型存储策略,包括对象存储(如Amazon S3)用于原始数据湖,NoSQL数据库(如Cassandra)处理非结构化数据,以及云原生数据仓库(如Snowflake、BigQuery)支持复杂分析。
- 服务与API层:通过RESTful或GraphQL API将处理后的数据暴露给下游应用,同时确保安全认证与访问控制。
- 编排与调度层:利用Kubernetes Jobs、Argo Workflows或Apache Airflow等工具,编排复杂的数据管道,管理任务依赖与执行周期。
架构模式上,数据网格(Data Mesh) 作为一种新兴的分布式架构理念,强调将数据作为产品,由领域团队自主管理其数据管道与服务,正成为大规模云原生数据处理的重要演进方向。
三、实践路径与挑战
在实践中,构建云原生数据处理服务需循序渐进:
- 评估与规划:明确业务需求、数据规模与处理延迟要求,选择合适的技术栈与服务模型(如自建K8s集群或采用托管服务)。
- 渐进式迁移:对于遗留系统,可采用Strangler Fig模式,逐步将功能迁移至云原生服务,而非一次性重构。
- DevOps与DataOps融合:将数据处理管道纳入CI/CD流程,实现数据代码的版本控制、自动化测试与持续部署,提升数据质量与交付速度。
- 安全与治理:实施端到端的数据加密(传输中与静态)、基于角色的访问控制(RBAC),并建立数据血缘追踪与合规性审计机制。
面临的挑战包括:跨云/混合云环境的数据一致性、处理成本优化(避免云资源浪费)、以及确保在高度分布式系统中数据的准确性与时效性。
四、未来展望
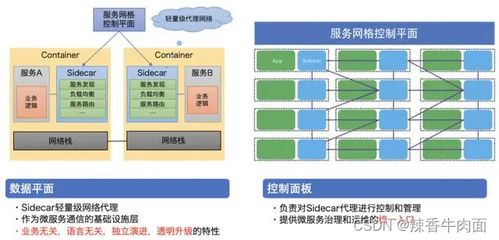
随着边缘计算、AI/ML的深度融合,云原生数据处理服务正朝着智能化与泛在化发展。服务网格(如Istio)将加强服务间通信的管理,而Serverless与FaaS的演进将进一步抽象基础设施复杂度,让开发者更专注于数据处理逻辑本身。
云原生架构为数据处理服务带来了前所未有的灵活性与效率。通过遵循其设计原则,合理选用技术组件,并持续迭代实践,组织能够构建出响应迅速、稳健可靠的数据处理能力,从而在数据洪流中捕获核心价值,驱动创新与增长。
如若转载,请注明出处:http://www.ftvhtj.com/product/74.html
更新时间:2026-06-19 07:33:55